
写在前面:
面试和组里的同门撞车了,一般一次招聘不会要同一来源的两个人,作为后来者,感觉面试官面到我已经完全不认真了,问我的问题也比问同门的难几个level,而且完全没在听我的自我介绍,在我讲实习的时候也在办公没理我,甚至还让我等了他好久。
不过他问的一些问题虽然常规,却也确实问住我了,实习缝纫机踩久了,KV存储引擎忘完了,在此做一下反思学习,不会/忘了的问题:
- 写延迟的成因,没回答全,只记得再write中的makeroom函数中,具体有哪些已经忘记了,只回答了leveldb的immutable memtable的下刷、L0层sstable过多。
- LSM tree为什么要设置为高于两层,这么设计的目的是什么?
- c++ deque的底层实现
LSM再学习
以我的理解而言,以LSM tree作为存储结构的引擎,提高性能的要点在于log与sort的平衡,sort的核心在于compaction
1. compaction的类型
rocksdb支持多种不同的compaction算法:Leveled compaction、Tiered compaction、FIFO compaction
1.1 Level compaction
参考自rocksdb的wiki
在Disk 里面维持了多级level的SStable,而且每层维持“唯一一个” “Run”。
Run的两个条件:
- SSTable有序
- SSTable的range没有交集
层的划分是以size为标准的,Ln+1.size() = 10 * Ln.size(),当层中sstable的总size超过大小则触发向下的compaction
- L0 -> L1
当L0sstable的数量到达预定值时触发,一般会选中全部L0层的sstable进行compaction,向L1层重叠的sstable合并。
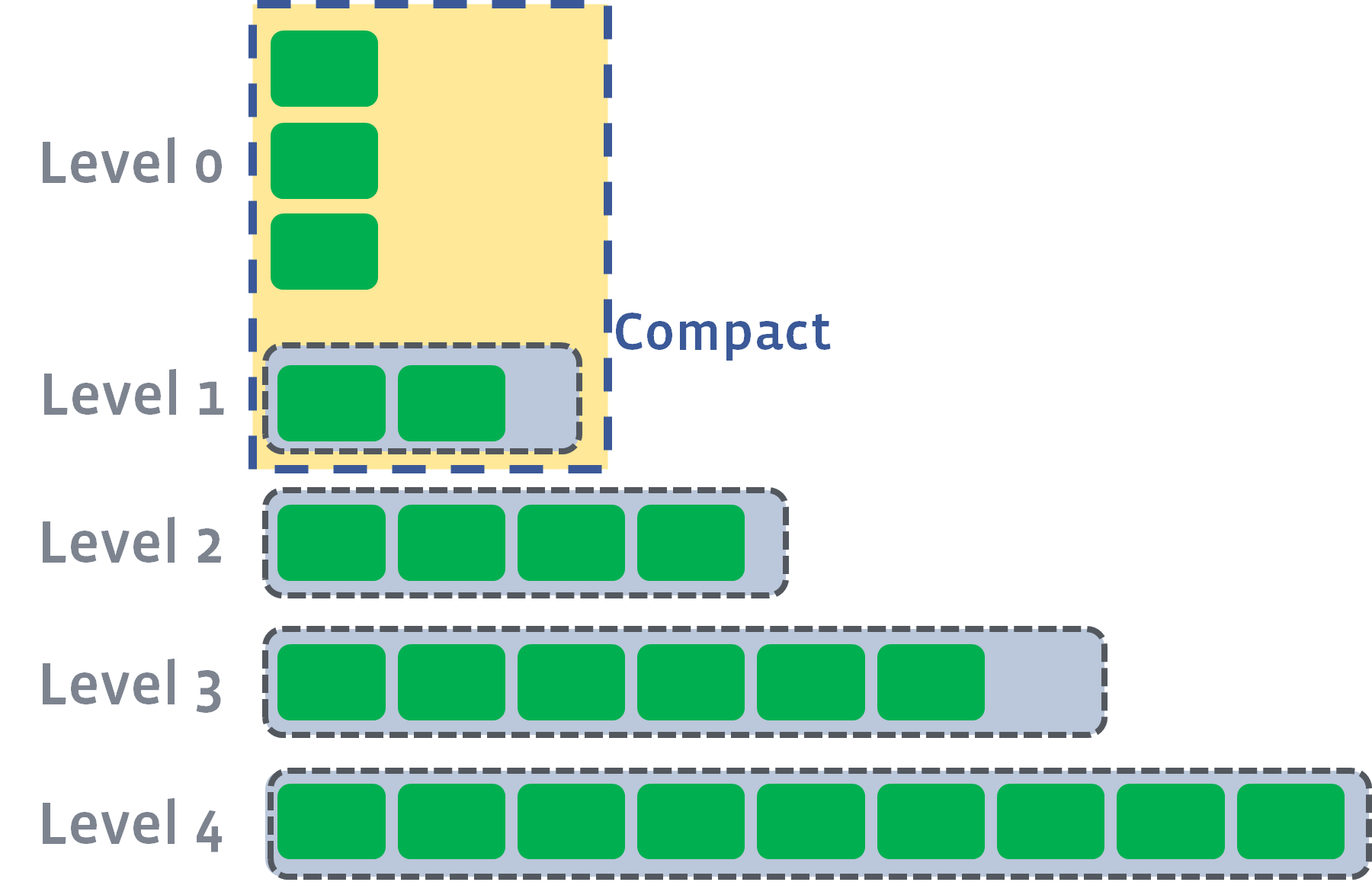
这里的合并一般是单线程的,因此可能是瓶颈,也有应对策略,叫做sub-compaction,这种应对策略不是专为此种场景设计的,所有比较重的compaction任务都可以做sub-compaction拆分,但是此功能是默认关闭的,详见后面。
- Ln -> Ln+1
如果Ln层的sstable超过了预定的size,则会选择至少一个继续向下compaction,这个过程是可以并发的,如图:
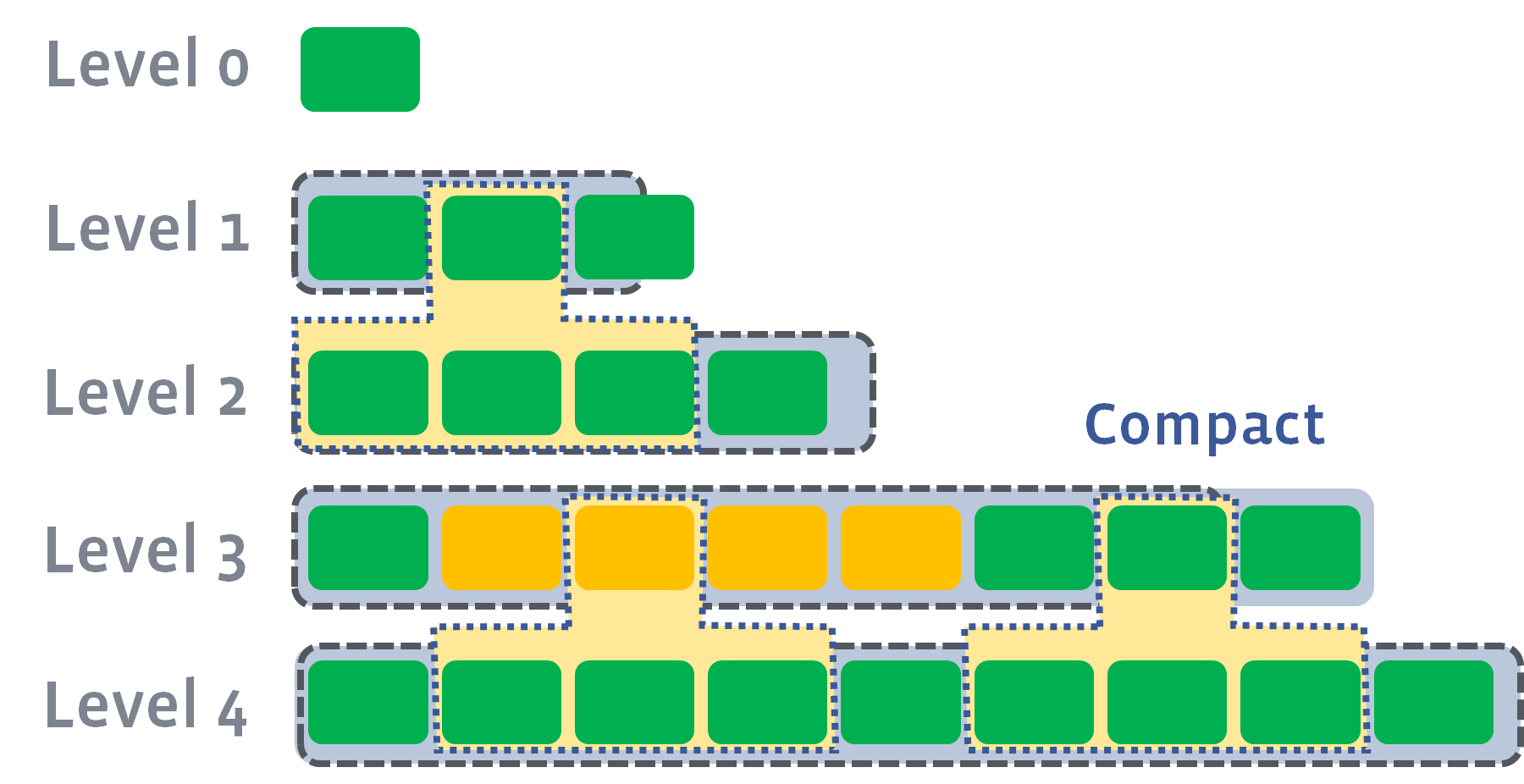
最大线程数是由 max_background_compactions来控制的。
在代码实现上,compaction的触发是依赖计算分数来确定的:
Score(L0) = file_num / max(
level0_file_num_compaction_trigger,max_bytes_for_level_base)这两个都是由用户手动设置的,顾名思义。
Score(L>0) = total_file_size / max_bytes_for_level
综上,L0层触发compaction的主要来源就是数量超限,L>0的触发来源是size超限,当然,以leveldb为例,还有其他触发compaction的入口,如:
mutable memtable -> imutable memtable -> minor compaction
在Get接口中,如果一个文件被访问多次都没命中,就会触发compaction
- 在每次get到数据时,会将其访问的上一层的(也可以说是访问的上一个)文件的allowed_seeks - 1,当allowed_seeks归0时,触发compaction
手动触发
level file size的选择
可以手动,也可以自动(level_compaction_dynamic_level_bytes),据官方说每一层是上一层的10倍最好。
level_compaction_dynamic_level_bytes = false
此时需要设置L0层的size(max_bytes_for_level_base ),倍数(max_bytes_for_level_multiplier),权值(max_bytes_for_level_multiplier_additional),计算公式为
1
Target_Size(Ln+1) = Target_Size(Ln) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_additional[n]`。`max_bytes_for_level_multiplier_additional
level_compaction_dynamic_level_bytes = true
此时需要设置L0层的size(max_bytes_for_level_base ),层数(num_levels),最高层的size(level n size),计算公式为
1
Target_Size(Ln-1) = Target_Size(Ln) / max_bytes_for_level_multiplier
1.x Sub-compaction
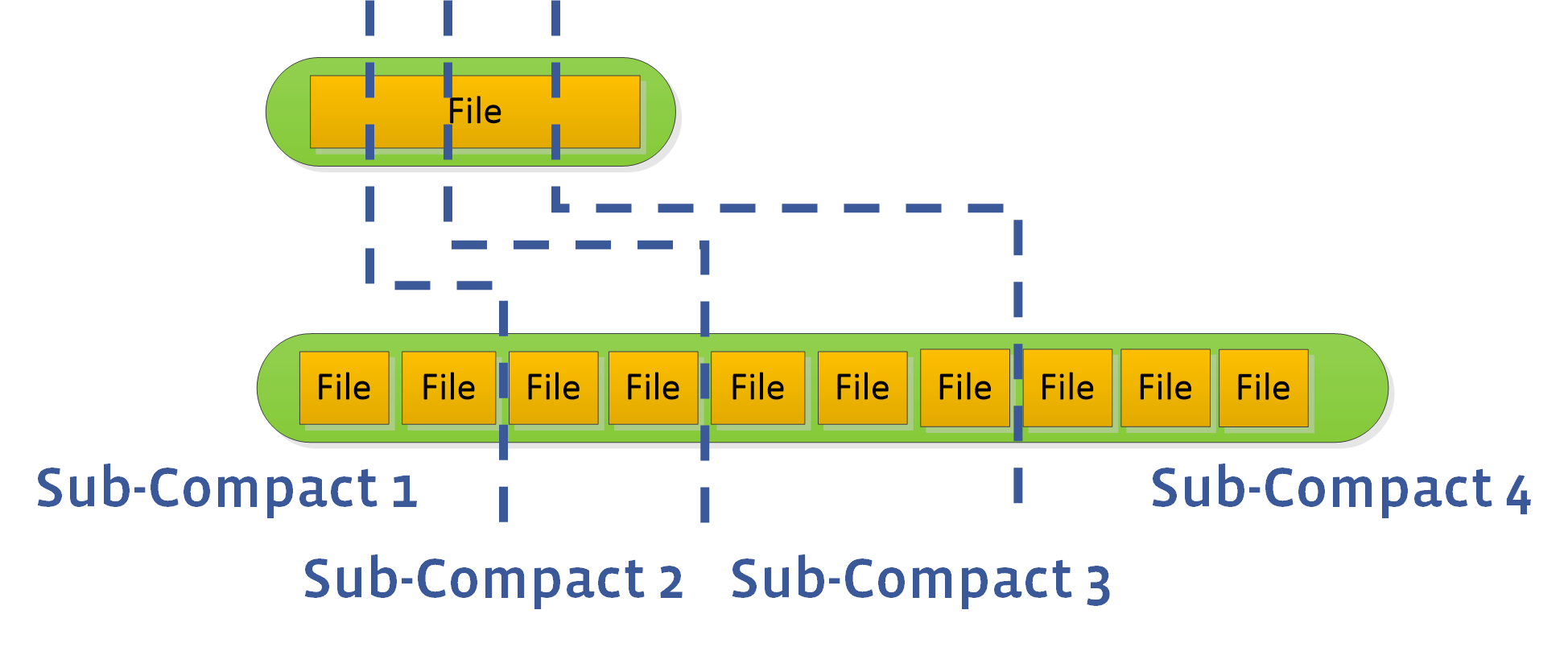
官方介绍说的有点模糊,对于sub-compaction的设计有版本的迭代,所以这里参考了这篇博客先解释大概原理
v7.6之前大致流程如下:
- 选中需要compaction的L0、L1文件
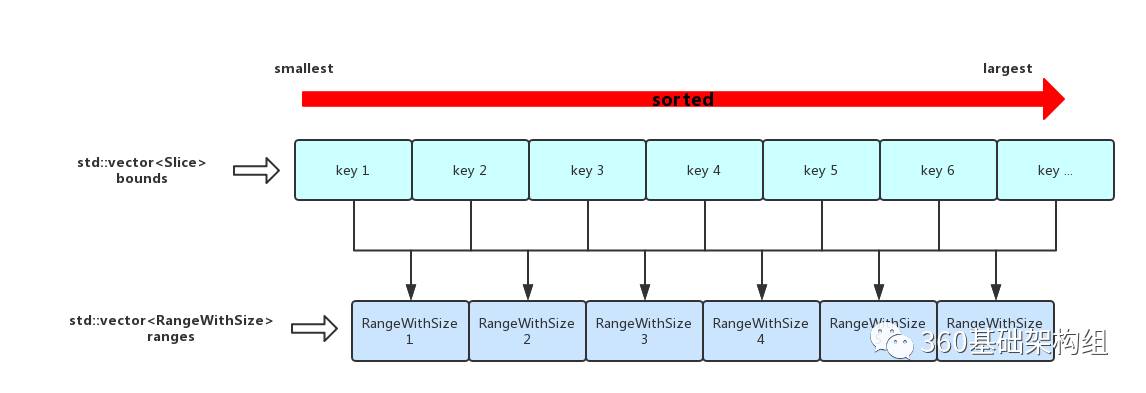
- 生成并排序bounds,如图,生成后根据slice 排序 并 去重 得到彼此独立的边界
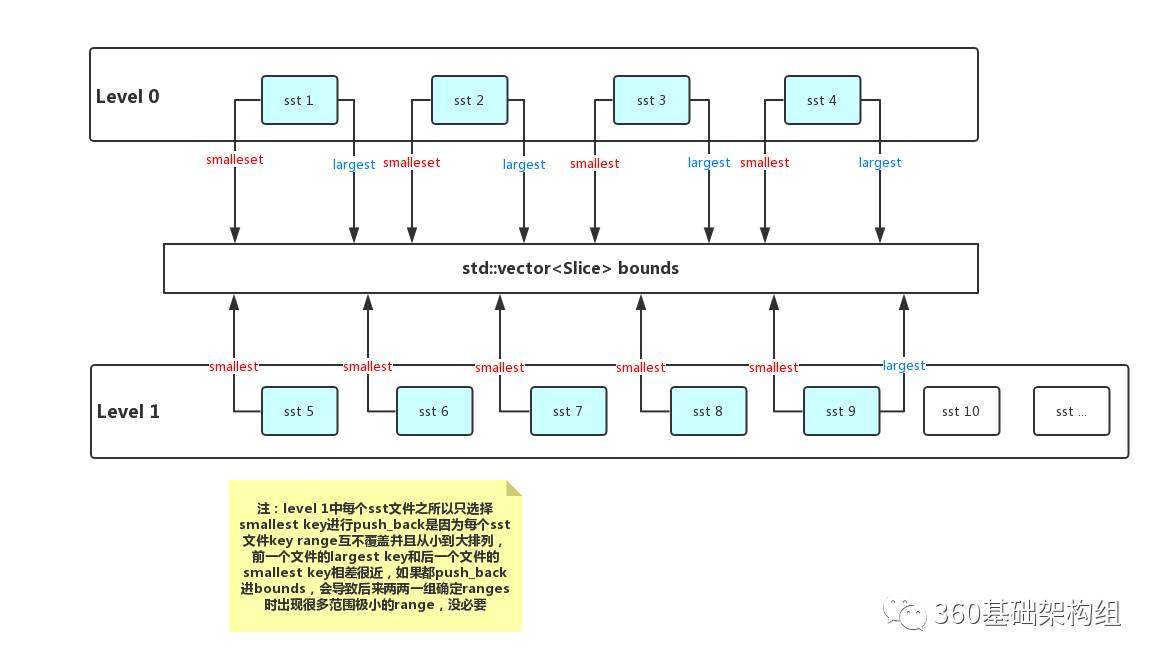
- 生成ranges,如图,将range的边界和文件的总大小一同保存到RangeWithSize,同时计算本次合并的总数据量sum
确定subconpactions,可以理解为生成实际的任务数量/sub-compaction的线程数,据博客介绍,这个值基于三个参考值:
- 用户配置的max_subcompaction
- 第3步的ranges.size()
- 这里不知道是不是作者笔误,他想写的可能是max_output_files = sum / max_file_size?
综上:
subconpactions.size() = min(max_subcompaction, ranges.size(), max_output_files)
任务分配,根据subconpactions.size()确定每一个线程应该分到多大的size,根据size划分最终的key range,生成任务,交给compaction线程去做操作
根据官方的wiki所述,在v7.6之后采用了一种分区的逻辑(The logic for partitioning)来优化sub-compaction,将输入文件切成最多128个partitions,在执行上述操作
2. 写延迟(Write stalls)
官方的说明文档在这里
- 背景
rocksdb在下刷或compaction无法跟上写入速度时会受控减慢写入速度,如果不这样做的话会造成空间放大和读放大
这两个放大的主要成因是数据没有及时的被推到更高层,导致相同数据的不同版本大量存在,造成空间放大,各层尤其是L0层文件数量变多导致了读放大。
写延迟的触发检测是列族级别的,但一旦触发就会影响整个db。当触发了写延迟时,rocksdb将速度降低到delayed_write_rate(通常是在写之前sleep 1ms),当情况很糟糕时,写入会低于这个值,甚至停止写入。
- 写延迟的原因
memtable太多
rocksdb允许多个memtable存在,其实就是在一定程度上允许minor compaction延迟,但是当immutable memtable过多时会占用内存、降低查找效率,immutable memtable的最大数量受到参数
max_write_buffer_number控制,当memtable数量为n,且max_write_buffer_number> 3时:- 3 < n < max_write_buffer_number,此时会进行写延迟
- n >= max_write_buffer_number,此时会写停止
L0的文件过多
当L0文件数量达到参数
level0_slowdown_writes_trigger时,会进行写延迟降速,当到达level0_stop_writes_trigger时,会直接停止写入,等待L0->L1的compaction结束有太多等待compaction的字节
当估算的compaction字节到达
soft_pending_compaction_bytes时,会进行写延迟,到达hard_pending_compaction_bytes时,会完全停止写入
- 缓解写延迟的方法
- 如果是下刷引起的写延迟:
- 增多
max_background_jobs,增多下刷线程数 - 调大memtable的最大数量(
max_write_buffer_number)以减小immtable memtable的size
- 增多
- 如果是L0文件过多或待compaction的字节太多:
- 增多
max_background_jobs,增多下刷线程数 - 调大
write_buffer_size以得到更大的memtable来减小写放大 - 调大
min_write_buffer_number_to_merge
- 增多
其他的方法就