
HappyFishingTime
摸鱼幻♂想♂乡,论文、技术总结与牢骚
Raft查漏补缺-好久没看而忘记的知识
写在前面:
腾讯TDSQL管控二面,虽然整体答得还可以,但是raft的记忆缺失比较严重,尤其是联合一致部分,我只记得三个状态,细节忘记了,这里再查漏补缺,回忆一下raft。
Raft查漏补缺
1. 状态机转移图
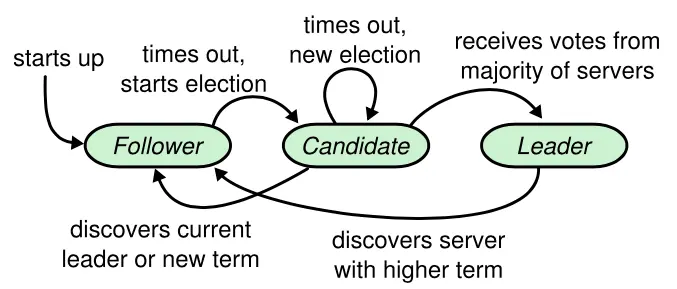
2. 阻止选票瓜分(或者说解决活锁问题)
- 随机超时,使不同的candidate发起选举的时间错开
- pre-vote
3. 影响正常选举过程的情况
- candidate收到了其他leader的心跳
- item大于自身则回到follower
- item小于则拒绝
- 选票被瓜分,见上
- candidate日志不全,缺少了已经提交的日志,即follower的日志比candidate新
- 拒绝
- 在新旧配置交接时,被移除的节点由于没有收到心跳会超时自增任期成为candidate,然后导致被移除的节点成为了leader
- 引入类似lease的机制,在收到leader心跳后的一段时间内不会接受其他leader的心跳
4. 日志
日志匹配特性
- 如果不同日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
- 如果不同日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也都相同。
日志同步
找到最大匹配的日志,之后的日志强行与leader同步。
日志提交
- 只能提交当前任期的日志,旧任期的日志通过复制来达成一致。
原因是旧任期的日志即使被复制到了多数也可能被新的leader覆盖,如图所示:
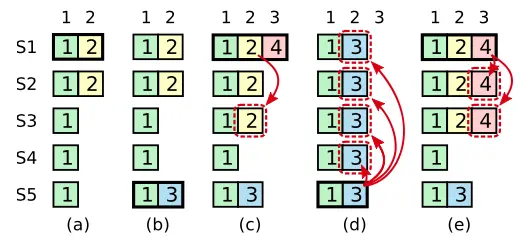
在 (a) 中,S1 是 leader ,部分地复制了索引位置 2 的日志条目。
在 (b) 中,S1 崩溃了,然后 S5 在任期 3 中通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。
然后到 (c),S5 又崩溃了;S1 重新启动,选举成功,继续复制日志。此时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。
如果 S1 在 (d) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。但是,在崩溃之前,如果 S1 在自己的任期里复制了日志条目到大多数机器上,
如 (e) 中,然后这个条目就会被提交(S5 就不可能选举成功)。 在这种情况下,之前的所有日志也被提交了。
- 联合一致日志计算提交时,如果leader不在新的配置中,不把自身计算在其中
5. 成员变更
联合一致(联合共识)算法
如果将配置变更操作交由一条日志来做的话会存在图中的问题:
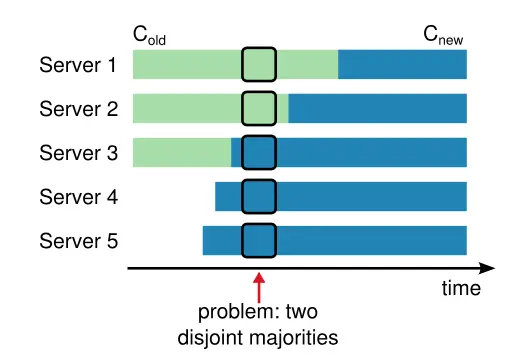
在箭头所示的时间节点,S1和S2可以在旧配置下选出leader,S3, 4, 5可以在新配置下选出leader,这样就发生了脑裂。
解决方法就是引入联合一致态:
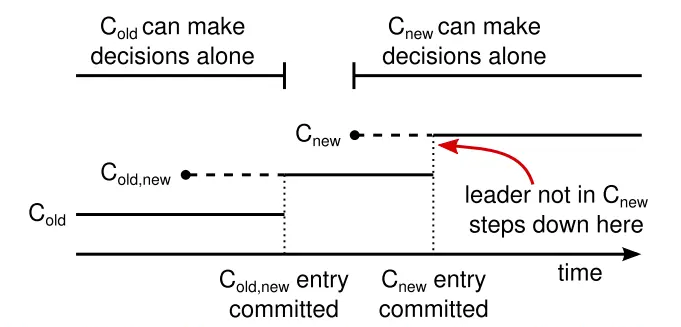
大致的流程:
- leader收到新配置后,会添加C-old,new日志,添加了C-old, new日志的节点会用该配置来做决策。又因为leader有C-old, new日志,因此C-old, new会按照新配置进行日志commit判定
- 如果leader中途挂了,那么新配置可能生效也可能不生效,取决于新leader是否有这条日志
- C-old, new被提交,就能保证有新配置的节点一定能成为leader,因此就可以进入下一个阶段
- leader添加C-new日志,在C-new提交后,如果当前leader不在新配置中,则在此时退出